-
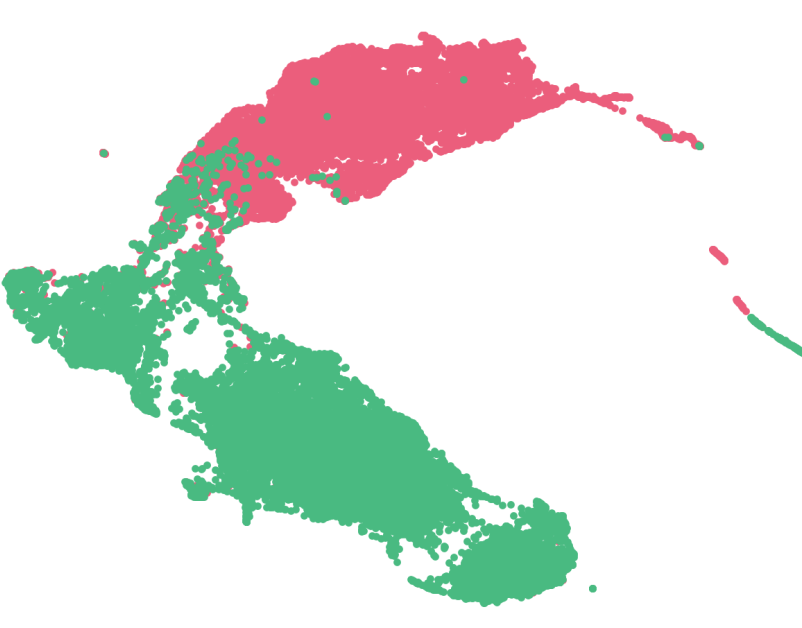
Deep learning models, such as neural networks, build abstract representations of data during the training phase. In this stage, the goal is to optimize a cost function—either by minimizing or maximizing it—using algorithms like those from the gradient descent family. In neural networks, this process is applied to each layer of the model. Thus, each…
-
Introduction With the apparition of internet, a large amount of data have been generated. In fact, this a exponential growth. For example, each day about 500M tweets are sent, 95M photos and videos are shared in Instagram, 500M photos are been uploaded. This exponential growth has allowed the use of new techniques in Artificial Intelligence.…